Modelado Dimensional: La base para un buen análisis de datos
El modelado dimensional organiza datos en hechos y dimensiones, logrando reportes claros e insights confiables para mejores decisiones.
Sep 2
/
Douglas Quintero
Cuando hablamos de analítica y de cómo estructurar los datos para responder preguntas del negocio, uno de los temas más importantes es el modelado dimensional. Este enfoque ha sido la base de los almacenes de datos modernos y, a pesar de los cambios en tecnología (data lakes, delta lakes, Fabric, etc.), sigue siendo esencial porque nos permite organizar la información de manera que sea fácil de entender, consultar y analizar.
El modelado dimensional organiza los datos en dos grandes componentes:
- Hechos: los números que queremos analizar (ventas, ingresos, producción, consumo de energía, etc.).
- Dimensiones: el contexto que explica esos números (producto, tiempo, cliente, ubicación, canal, etc.).
La relación entre ambos se refleja en una tabla de hechos al centro y varias tablas de dimensiones alrededor, lo que comúnmente se conoce como esquema en estrella.
La idea es simple: cada fila de la tabla de hechos representa un evento (una transacción, un pedido, un movimiento de inventario, etc.), y las dimensiones nos permiten filtrar, agrupar y entender esos números desde diferentes perspectivas.
Las dimensiones no son todas iguales; dependiendo de su rol, se clasifican en distintas categorías:
- Dimensión degenerada: atributos que se almacenan directamente en la tabla de hechos y no requieren una tabla aparte.
Ejemplo: en un registro de facturación, el número de factura o el código de transacción puede estar en la tabla de hechos sin tener una dimensión separada.
- Dimensión conforme: se comparte entre diferentes tablas de hechos, asegurando consistencia en todo el modelo.
Ejemplo: la misma tabla de clientes usada tanto en ventas como en cobranzas, de modo que un “Cliente 123” tenga la misma definición en todos los procesos.
- Dimensión junk: agrupa indicadores dispersos de baja cardinalidad (banderas, estados, códigos internos) para simplificar el modelo.
Ejemplo: estados de un pedido como “urgente = sí/no”, “entregado a tiempo = sí/no”, “requiere inspección = sí/no”. En lugar de crear una tabla para cada bandera, se consolidan en una sola dimensión.
- Dimensión de múltiples roles: una misma tabla que se interpreta de distintas formas.
Ejemplo: una dimensión de fecha utilizada como “fecha de creación del contrato”, “fecha de aprobación” y “fecha de vencimiento”.
- Dimensión de cambio lento (Slowly Changing Dimension – SCD): maneja atributos que cambian con el tiempo. Estos cambios pueden gestionarse de distintas maneras:
- SCD Tipo 1: se sobrescribe el valor anterior con el nuevo, sin conservar histórico.
Ejemplo: el área de un empleado cambia de “Marketing” a “Ventas”, y en la tabla solo queda registrado “Ventas”.
- SCD Tipo 2: se crea una nueva fila por cada cambio, manteniendo el histórico completo.
Ejemplo: si un cliente cambia de ciudad, la tabla guarda una fila con la ciudad anterior y otra con la nueva, cada una con fechas de vigencia.
- SCD Tipo 3: se conserva solo un histórico limitado en columnas adicionales.
Ejemplo: un producto que cambia de categoría mantiene en una columna la “Categoría actual” y en otra la “Categoría anterior”, pero no se guardan todos los cambios pasados.
- SCD Tipo 4: se usa una tabla aparte para almacenar el histórico.
Ejemplo: una tabla de “Clientes actuales” con la información vigente y otra tabla “Clientes_histórico” que guarda los cambios de direcciones, teléfonos, etc.
- SCD Tipo 5: combina los tipos 1 y 2, manteniendo un registro del valor actual en la dimensión principal y los históricos en una tabla adicional.
Ejemplo: un cliente con su dirección actual siempre visible en la tabla de dimensión, pero con todos los cambios registrados en una tabla histórica.
- SCD Tipo 6: combina los tipos 2 y 3: se añade una nueva fila por cada cambio (como en Tipo 2), pero además se guarda en columnas el valor actual y el anterior inmediato.
Ejemplo: en una tabla de productos, al cambiar el precio se crea una nueva fila con la versión del producto, pero también se conserva en columnas el “precio actual” y el “precio anterior”.
- Dimensión de tiempo: facilita el análisis por periodos (días, meses, trimestres, años, etc.).
Ejemplo: un reporte de producción puede analizarse por mes, trimestre o año usando la dimensión de tiempo.
- Dimensión jerárquica: organiza atributos en niveles.
Ejemplo: un catálogo de productos que se agrupa por Categoría → Subcategoría → Producto.
- Dimensión virtual: creada dinámicamente en consultas, sin necesidad de estar almacenada físicamente
Ejemplo: en un dashboard de logística, generar una dimensión calculada de “tipo de cliente” (mayorista o minorista) a partir de reglas de negocio sin que exista una tabla almacenada.
En el centro están los hechos, que representan los eventos que queremos analizar. Cada hecho se mide a través de medidas: métricas numéricas como montos, cantidades, promedios o porcentajes.
Las mejores prácticas para definir hechos y medidas incluyen:
- Escoger métricas que realmente respondan a preguntas del negocio.
- Usar unidades de medida consistentes (para evitar confusiones).
- Preferir medidas aditivas (que se puedan sumar a lo largo de las dimensiones), ya que simplifican los análisis.
- Precalcular las medidas que se consultan frecuentemente para mejorar el rendimiento.
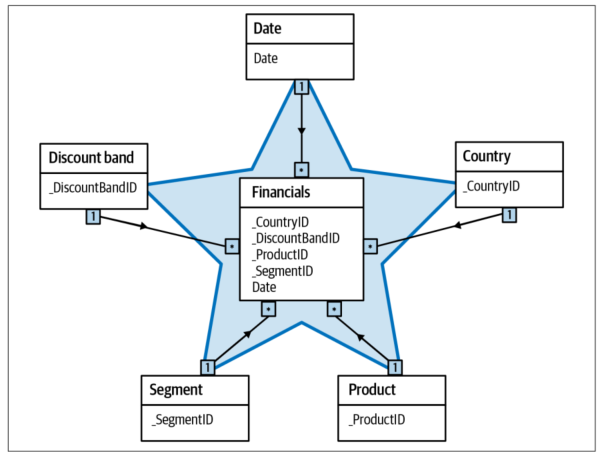
Existen diferentes maneras de estructurar un modelo dimensional:
- Esquema en estrella: simple, fácil de entender y con gran rendimiento para consultas analíticas.
- Esquema en copo de nieve: normaliza las dimensiones para reducir redundancia, pero lo vuelve más complejo.
- Constelación de hechos: cuando varias tablas de hechos comparten dimensiones comunes, permitiendo un análisis más avanzado en entornos complejos.
En un mundo donde hablamos de data lakes, lakehouses y Microsoft Fabric, uno podría pensar que el modelado dimensional ya no es necesario. Pero la realidad es que, incluso con nuevas arquitecturas, el modelo dimensional sigue siendo la manera más efectiva de organizar la información para el análisis.
Es la diferencia entre tener datos “en bruto” y tener información lista para responder preguntas de negocio. Un buen modelo dimensional permite construir dashboards claros, responder consultas rápidas y, sobre todo, asegurar que las decisiones se basen en datos consistentes.

